





Risk Management Solution Challenges & Architecture Patterns
Risk and its management remains one of the industry's hottest topics, and for good reason.
A great deal of work is being done in building risk-computing platforms that can handle high-volume trading products while achieving high performance, scalability, and improved reliability. For instance, most large banking infrastructures process millions of derivative trades in a typical day, resulting in a large number of data inserts and updates. Once the data is loaded into the infrastructure, complex mathematical calculations are required in near real-time to calculate intraday positions.
Implementations like this are designed to meet several business goals, including the following:
- Providing a capability to collect and analyze market data and trading events, potentially using complex business rules
- Providing a centralized location for aggregation at a house-wide level and subsequent analysis of market data, counter-parties, liabilities, and exposures
- Supporting the execution of liquidity analysis on an intraday or multi-day basis while providing long-term data retention capabilities
- Providing strong but optional capabilities for layering in business workflow and rules-based decisioning as an outcome of analysis
- Providing a capability to respond to business events quickly, react with intelligence, and (where applicable) provide high-quality answers
Typical risk management calculations require running separate simulations for each time point and product line to derive higher-order results. The resulting intermediate data needs to be aligned to collateral valuations, derivative settlement agreements, and any other relevant regulations to arrive at a final portfolio position. Further, these risk management calculations require a mechanism to pull in data that needs be available for reference for a given set of clients and/or portfolios.
At the same time, long-term positions need to be calculated for stress tests, typically using at least 12 months of data pertaining to a given product set. Finally, the two streams of data may be compared to produce a credit valuation adjustment value.
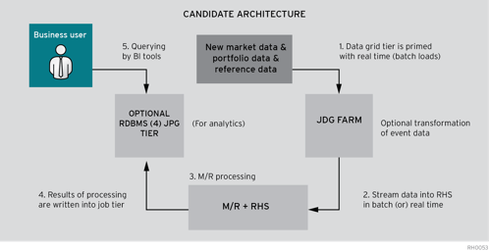
There are broad needs for two distinct data tiers that can be identified based on the business requirements above.
First, it is clear from the image above that data needs to be pulled in near real-time and accessed in a low-latency pattern similar to the calculations performed on the data. The design principle here needs to be "Write Many, Read Many," with an ability to scale out tiers of servers.
In-memory data grids (IMDGs) are well suited for this use case, because they support a high write rate. A highly scalable and proven implementation of a distributed data grid that gives users the ability to store, access, modify, and transfer extremely large amounts of distributed data may be preferable here. Further, these products offer a universal namespace for applications to collect data from different sources, offering the aforementioned functionality. A key advantage here is that data grids can pool memory and can scale out across a cluster of servers in a horizontal manner. Further, computation can be pushed into the tiers of servers running the data, grid as opposed to pulling data into the computation tier.
To meet the needs for scalability, fast access, and user collaboration, data grids support replication of data sets to points within the distributed data architecture. The use of replicas gives multiple users faster access to data sets and enables the preservation of bandwidth, since replicas can often be placed strategically close to or within sites where users need them. Other desirable properties are support for wide area network replication, clustering, out-of-the-box replication, and support for multiple language clients.
The second data access pattern that requires support is storage for data ranging from the next day to months and years. This is typically large-scale historical data. The primary data access principle here is "Write Once, Read Many." This layer contains the immutable, constantly growing master data set stored on a distributed file system like the Hadoop Distributed File System (HDFS). With batch processing (e.g., MapReduce) arbitrary views -- so-called batch views -- are computed from this raw data set. So Hadoop (MapReduce) is a perfect fit for the concept of the batch layer. Besides being a storage mechanism, the data stored in HDFS is formatted in a manner suitable for consumption from any tool within the Apache Hadoop ecosystem like Hive or Pig or Mahout.
Open and horizontally scalable architectures offer many benefits, including high transaction throughput, speed of analysis, and performance gains. From an industry perspective, one can notice a slow movement from service-oriented architectures to event-driven architectures.
Computing arbitrary functions on a large and growing master data set in real-time is a daunting problem. There is no single product or technology approach that can satisfy all business requirements. Instead, big data solutions require a variety of tools and techniques. As organizations move to these architectures to address risk better, open-source solutions -- including data grids -- are forming a large portion of such innovations. With the significant flexibility, scalability, value, and incredible rate of innovation offered by open-source solutions, this only makes sense as organizations evaluate their risk management systems and architectures.
As Chief Architect of Red Hat's Financial Services Vertical, Vamsi Chemitiganti is responsible for driving Red Hat's technology vision from a client standpoint. The breadth of these areas range from Platform, Middleware, Storage to Big Data and Cloud (IaaS and PaaS). The ... View Full Bio










